 USharing
USharing概率就是上帝在掷筛子——在18世纪,这是神职人员对概率的理解。为了证明上帝的存在,英国业余数学家托马斯·贝叶斯发明了概率统计学原理,他发现了古典统计学中的一些缺点,并在统计当中引入了一个主观因素(即先验概率)形成了自己的“贝叶斯统计学”。
然而他的理论在当时并不受认可。当然贝叶斯直到去世都没有印证上帝的存在,他的观点简单平淡:“用客观的新信息更新我们最初关于某个事物的信念后,我们就会得到一个新的、改进了的信念。” 这个研究成果,直到他死后的两年才于1763年由他的朋友理查德·普莱斯帮助发表。1774年,法国数学家皮埃尔-西蒙·拉普拉斯才给出了我们现在所用的贝叶斯公式的表达。
贝叶斯公式
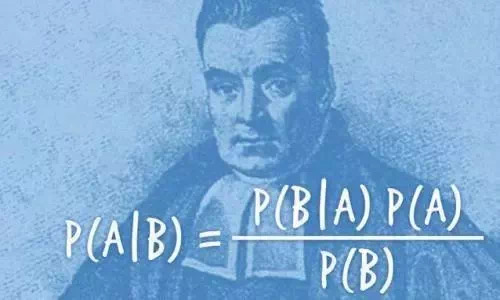
所谓的贝叶斯定理源于他生前为解决一个“逆向概率”问题写的一篇文章:“假设袋子里有白球和黑球,我们事先并不知道袋子里面黑白球的比例,而是闭着眼摸出一个(或好几个)球,观察这些取出来的球的颜色之后,我们可以就此对袋子里面的黑白球比例做出什么样的推测?”
贝叶斯定理实际上就是条件概率公式:设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率(conditional probability)为:
P(A|B)=P(AB)/P(B)
P(A)是A的先验概率,之所以成为先验是因为它不考虑任何B的因素,P(B)同理;
P(A|B)实在B发生时A发生的条件概率,称坐A的后验概率,P(B|A)同理。
贝叶斯定理通俗地讲,就是当你不能确定某一个事件发生的概率时,你可以依靠与该时间本质属性相关的事件发生的概率去推测该事件发生的概率
贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件Bi的概率),设B1,B2,…是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有:
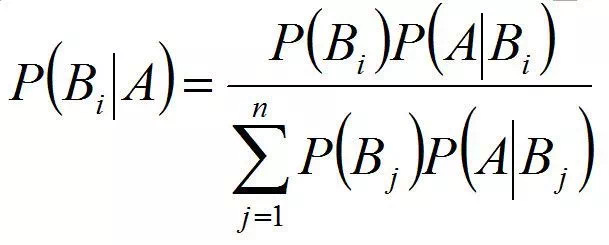
上式即为贝叶斯公式(Bayes formula),Bi 常被视为导致试验结果A发生的“原因”,P(Bi)(i=1,2,…)为先验概率;P(Bi|A)(i=1,2…)为后验概率。
通过联系A与B,计算从一个时间发生的情况下另一时间发生的概率,即从结果上溯到源头(逆向概率)。
贝叶斯定理与经典统计学推断方法截然不同,它建立在主观判断的基础上,使用者可以不需要客观证据,先估计一个值,然后根据实际结果不断修正,正式因为它的主观性太强,和注重客观事实研究的经典统计学背道而驰,最终连公式的发现者拉普拉斯都放弃了它,转投经典统计学。但随着计算机的发展,高速运算能力解决了贝叶斯定理所需的大量运算问题,它的威力才逐渐显现。
贝叶斯应用的经典案例
两个标志性的事件使贝叶斯方法渐渐受到学术界的重视:
一是联邦党人文集作者公案:哈佛大学统计学教授Fredrick Mosteller和统计学家David Wallance通过分析词汇在文章中出现的频率,来判定《联邦党人文集》中存在争议的12篇文章其作者到底是汉密尔顿还是麦迪逊。

这两个案例是贝叶斯应用的经典案例,但是限于当时的技术水平,贝叶斯的应用困难重重,主要的阻力来自于大量的计算,如1787年发生的联邦党人文集作者公案,David Wallance找了100个哈佛大学的学生来帮助处理数据,学生们用最原始的方式,用打字机把《联邦党人文集》打出来,剪下每个单词,按照字母表顺序将单词分门别类地汇集在一起,《联邦党人文集》中,已经确定作者的73篇文章:汉密尔顿写了9.4万字,麦迪逊写了11.4万字,可以想象这项工程有多枯燥浩大,Fredrick Mosteller和David Wallance花了十年的时间,才给这件事画上了一个完美的句号。
另一是天蝎号核潜艇搜救:数学家John Craven通过数学家、潜艇专家、海事搜救等各个领域的专家,按照他们的猜测评估某种情景出现的可能性,并根据贝叶斯公式得到了一张20英里海域的概率图:

每次寻找时,先挑选整个区域内潜艇存在概率值最高的一个格子进行搜索,如果没有发现,概率分布图会被“洗牌”一次,搜寻船只就会驶向新的“最可疑格子”进行搜索,经过几次搜索,潜艇果然被找到了。这种基于贝叶斯公式的方法在后来多次搜救实践中被成功应用,现在已经成为海难空难搜救的通行做法。
贝叶斯理论的伯乐

▲Frederick Jelinek
千里马常有,而伯乐不常有。谈起贝叶斯公式的应用,就不得不提起一个人——语音和语言处理大师Fred Jelinek,没有他,人们不知到多久以后才会知道语言还能被机器处理。
人们平时在说话时,脑子就是一个信息源。人们的喉咙(声带),空气,就是如电线和光缆般的信道。听众耳朵的就是接收端,而听到的声音就是传送过来的信号。根据声学信号来推测说话者的意思,就是语音识别。这样说来,如果接收端是一台计算机而不是人的话,那么计算机要做的就是语音的自动识别。同样,在计算机中,如果我们要根据接收到的英语信息,推测说话者的汉语意思,就是机器翻译;如果我们要根据带有拼写错误的语句推测说话者想表达的正确意思,那就是自动纠错。
在70年代以前,语音识别还停留在识别小词汇量、孤立词的方面
1973年,贾里尼克在IBM组建了语音识别的研究队伍,其中包括他的著名搭档波尔(Bahl),著名的语音识别 Dragon 公司的创始人贝克夫妇,解决最大熵迭代算法的达拉皮垂(Della Pietra)孪生兄弟,BCJR 算法的另外两个共同提出者库克(Cocke)和拉维夫(Raviv),以及第一个提出机器翻译统计模型的布朗。
在贾里尼克以前,科学家们把语音识别问题当作人工智能问题和模式匹配问题:
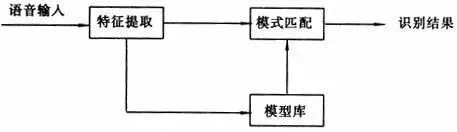
贾里尼克把它当成通信问题,他通过将贝叶斯公式和马尔科夫链结合,简化问题使计算机能够方便求解,从而解决了语音识别问题。
N-Gram是大量词汇连续语音识别中最常见的一种语言模型,模型基于独立输入假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。这个是个基于贝叶斯公式的统计语言模型。
贾里尼克对至今的语音和语言处理有着深远的影响,他的研究从根本上使得语音识别有实用的可能。自此之后,贝叶斯方法的应用延伸到各个问题领域,所有需要作出概率预测的地方都可以见到贝叶斯方法的影子,如今,贝叶斯更是机器学习的核心方法之一。
来源:公众号 轻松学高等数学
